The goal of this work is to provide relevant corpus representations for the manuscripts of British philosopher and social reformer Jeremy Bentham (1748-1832).

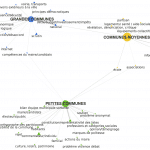
Main topics addressed in the Bentham corpus, based on clusters of concepts, showing the main concerns of Bentham’s writings, which map closely onto established research areas in Bentham studies. The network was produced by Cortext; colours and fonts were reformatted in Gephi based on Cortext’s gexf-format export
This is a large corpus, owned by University College London (UCL). Until recently, the manuscripts were for the most part untranscribed, so that very few people had access to the corpus to evaluate its content and its value. At UCL, the corpus is now being digitized and transcribed thanks to a large number of volunteers recruited through a crowd-sourcing initiative called Transcribe Bentham. The problem researchers are facing with such a corpus is clear: how to access the content, how to structure these (at the moment) 30,000 files, and how to get relevant access to this mass of data?
We first performed a lexical extraction in order to obtain the terms to model the corpus, using a technology called entity linking or wikification.
We then used CorText Manager to cluster the terms, and produce corpus visualizations, both static and dynamic through time. We used the following functions from the CorText platform:
– Network analysis: concept networks
– Heatmaps by decade: they show what areas of the corpus are more prominent per decade
– Tubes layout: evolution of concept clusters throug time
An interface showcasing project results so far is at: http://apps.lattice.cnrs.fr/bentham/
The work was presented at the 2016 Digital Humanities Conference in Krakow:
http://dh2016.adho.org/abstracts/372

Heatmap for the documents in the decade of 1820-1830; red shadowing indicates corpus areas that are more salient in this decade compared to the rest of the corpus.